
Performance is a big deal at Mixmax. Our users use the product all day, so we strive to make sure it’s a smooth and enjoyable experience. One area that we’ve recently put a lot of work into was improving the performance of the contacts autocomplete field in the compose window:
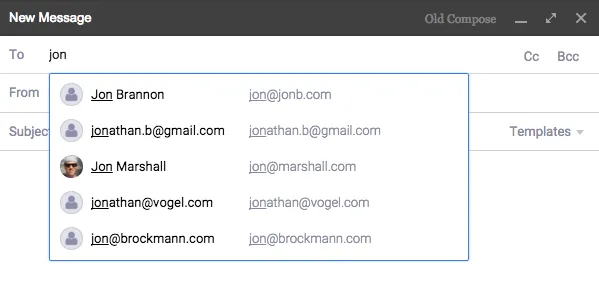
Our original implementation of autocomplete was very slow. When a user typed into the autocomplete field we’d fire off an ajax request to the server for results. This took 824ms (90th percentile) and felt very sluggish.
So where was the slowness? Our performance logging told us that the server-side lookup was very fast (9ms for 90th percentile), so the slowness was purely in the network. We needed to come up with a better solution that didn’t rely on the network; we needed to implement a client-side cache.
Designing a client-side cache
In an ideal world every result would be instant. In order to achieve that, we’d need to cache the user’s entire library of contacts client-side and perform a lookup immediately on every keystroke. However, it wasn’t feasible to store their entire contacts library client-side given that the average user has around 8,000 contacts (think: every unique person you’ve ever emailed). But we can get close.
What data structure to use?
Our autocomplete UI widget passes us a query string and we pass it back an array of contacts with ‘email’ and an optional ‘name’ property. So it’d be ideal if our cache data structure could easily map a query to some results in near-constant time. So this seemed ideal:
{
<query>: [<result 1>, <result 2>, ...]
}Here’s example data:
{
"b": [{"name": "Brad Vogel", "email": "bradv@mixmax.com"}, {"name": "Bob Jones", "email": "bob@mixmax.com"}],
"br": [{"name": "Brad Vogel", "email": "bradv@mixmax.com"}]
}Which API to use?
HTML5 has many client-side persistence APIs to choose from. There’s the usual ones: Cookies, Local Storage, Session Storage. Then there’s the newer APIs: IndexedDB and HTML5 File API.
Cookies were unrealistic because of their small size (4kb in Chrome) and that they’re sent to the server with every request, slowing down the entire site. Newer APIs like IndexedDB and HTML5 File API had limited browser support, more complex APIs, and were more challenging to debug in the browser. IndexedDB was by far the most attractive option given its “unlimited” storage, but its async APIs would have required more complex code.
We just needed a simple API that we could store 1000s of contacts in. So that left us with Local Storage. Its API is about as basic as it gets (global object window.localStorage), all reads/writes are synchronous, and it can hold a good amount of data (10MB in Chrome).
Dealing with storage size limitations
Local Storage is limited to just 10MB. Additionally, it’s UTF-16 encoded, so only you really only have half available even if you’re storing basic ASCII characters (side note: there’s discussion of removing this limit). Our data format is highly redundant with many contacts showing up for many query results, so we needed some sort of compression otherwise we’d be really limiting our cache.
As any CS textbook will tell you, compression comes down to a tradeoff of time vs storage. Our solutions would traverse this tradeoff.
First solution: use an out-of-the-box compression library
After some googling around, we found LZ-string - a purpose-built implementation of LZW compression for Local Storage. Perfect for our use case. It seemed to run in a reasonable amount of time when tested locally. So we wrote some code to cache autocomplete results in our format, serialize it as JSON, compress it through LZ-string, and then save it to Local Storage.
We let this solution run for a few days and watched our analytics closely as users’ caches began to fill up from their daily use of autocomplete. The results:
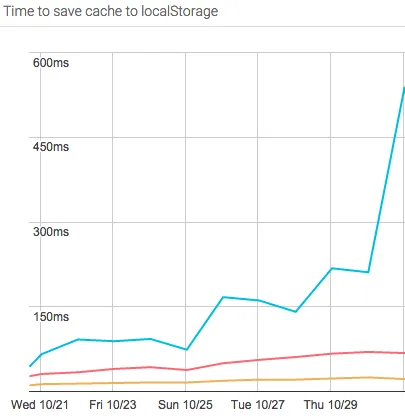
The lines represent the 99th, 90th, and 50th percentile time to save the cache in Local Storage
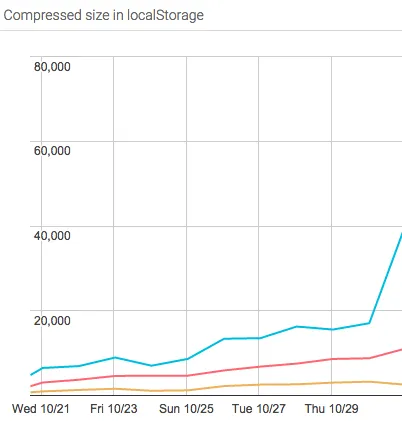
Length of string (JSON-encoded data structure) that gets saved in Local Storage.
The data was alarming: for the slowest 1% of users, it took 550ms to compress the cache and save it to Local Storage. The upside, however, was that LZ-string did a great job keeping the cache size small (<40k chars, so only 80kb (since UTF-16) of our 10mb limit). But a half second of stalling the browser was too slow.
Second solution: implement our own compression
Since LZ-string was doing a bit too good of a job compressing the results (at the expense of time), we needed a solution that offered a better balance. We decided to roll our own compression solution that simply stored unique email results separate from the queries. So this data structure:
{
"b": [{"name": "Brad Vogel", "email": "bradv@mixmax.com"}, {"name": "Bob Jones", "email": "bob@mixmax.com"}],
"br": [{"name": "Brad Vogel", "email": "bradv@mixmax.com"}]
}could be “compressed” to this:
{
"queries": {
"b": {
"timestamp": 1445794686069,
"results": [0, 1],
},
"br": {
"timestamp": 1445794732044,
"results": [0]
}
},
"emails": [{"name": "Brad Vogel", "email": "bradv@mixmax.com"}, {"name": "Bob Jones", "email": "bob@mixmax.com"}]
}In local testing, it didn’t do quite as well in the “space” category, requiring roughly 4x the space of the LZ-string compression. However, it ran an order of magnitude faster. So we rolled it out to production and waited a few days to collect real-world usage:
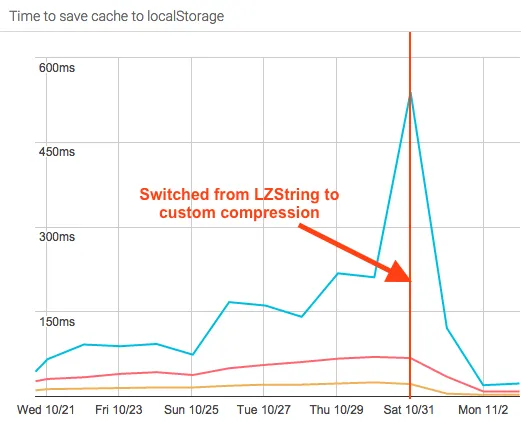
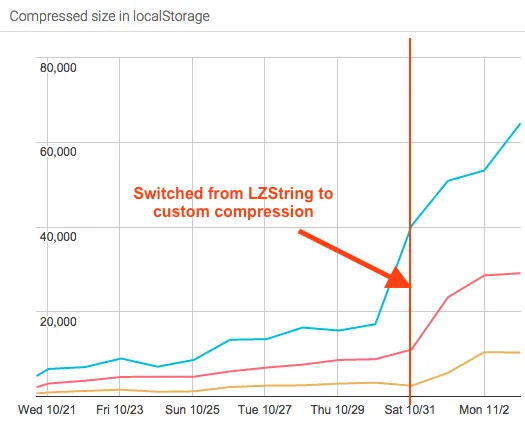
The results were as expected: the cache was significantly faster to compress (23ms for the 99th percentile!) but required 4x more storage. However, the larger storage (of 64k characters for 99th percentile) was well under the size limit (10mb) of Local Storage. So this was a much better time vs storage tradeoff.
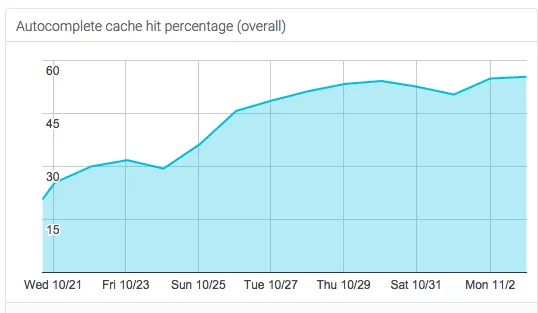
The best part is watching our overall “user happiness” metric steadily improve each day - the autocomplete cache hit rate (the % of queries that return immediate results) - is now up to 55%. All for just 23ms of time spent saving the autocomplete cache locally.
Conclusion
This project turned out to be the right balance between time spent engineering (just a few hours total) and improved user experience. We could farther improve it by:
- Using IndexedDB instead of Local Storage since it has “unlimited” storage. The only reason we didn’t do this in v1 was just that the asynchronous APIs made it a bit more complex to integrate it with our autocomplete widget. But this would be ideal so we’d never have to deal with a user hitting the Local Storage cache limit.
- Pre-warming the cache so a user’s first query is instant right after they install Mixmax. The server already knows who the user emails the most when first syncing, so it could just send those contacts down to the client on first load. We’d have to make our cache matching logic much smarter though to map search queries to those results.
The cache is currently growing unbounded so we’ll eventually need to cap it to a certain size (in LRU order). It’ll be interesting to watch the growth behavior and see where it plateaus out at the max number of distinct queries a user is likely to ever search for.
A key lesson in this project was to always measure everything. Don’t trust that off-the-shelf libraries will just work for your needs based on what they advertise. Most importantly, balance the needs of your users and time spent on the project. Even though solutions can be basic (such as using Local Storage in this case) you’re ultimately responsible for delivering the quickest solution that satisfies your users.
Like making products on the web fast? Come join us! Email careers@mixmax.com and let’s grab coffee!