
In the next series of blog posts, we’ll open you up to the technical inner workings of Mixmax and discuss how we evolved it from a simple prototype into a successful product that scales to many thousands of users. In this first post, we’ll tell you about what happened when Mixmax went out-of-control viral and how we quickly diagnosed and fixed a key bottleneck.
Launching a prototype
Mixmax started just 9 months ago. We kept our product in private beta with friends and family throughout the early months. But we knew we were on to something great. All of our early users loved it and even asked if they could pay for it. So we decided to polish it up a bit more and then “soft launch” Mixmax publicly for the first time on Product Hunt in mid-January. We didn’t expect much—perhaps a few hundred downloads—well within the capacity that we planned for our prototype to support.
At Mixmax we follow the principle: make it valuable, then easy, then fast. Our product was still a prototype, built to prove a product-market hypothesis with a small user base. We had focused much of our attention on the delightful UX details that make Mixmax so wonderful to use. We deferred work on performance and scaling until we knew were on the right product path. Or architecture was primitive and fragile: all reads and writes were hitting our Mongo database directly with no caching layer in-between. We over-relied on Meteor framework primitives (live subscriptions using oplog tailing) to implement features of our app. It was exactly what it needed to be (and not a bit more!) for a prototype.
Then came ProductHunt launch day on Jan 13th. We quickly rose to #3 on ProductHunt. We were being downloaded thousands of times and there were lots of tweets about how we were the best Gmail add-on. Our traffic continued to rise throughout the day:
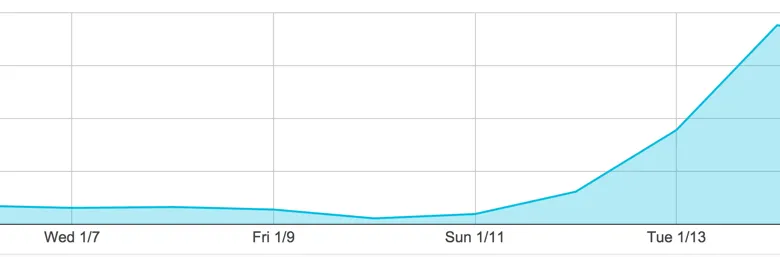
Then, that’s when we started hitting performance issues. Our TTFB server time slowly crept up to almost 5 seconds—time that the user spent staring at our loading spinner. By Thursday afternoon, our traffic tapered off and users were uninstalling because they couldn’t log in.
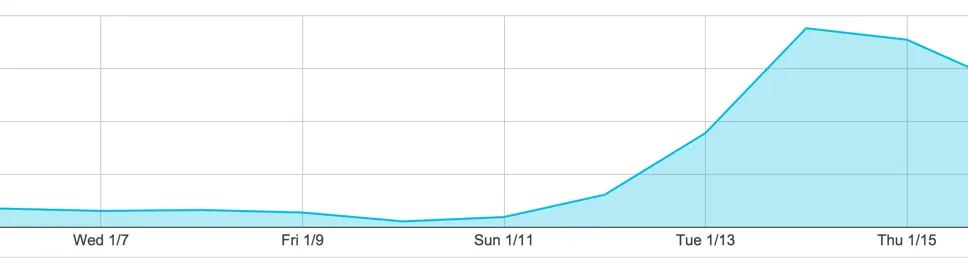
This was devastating. We needed to fix these performance issues ASAP to keep our new users happy.
Determining the bottleneck
First, a bit about Mixmax architecture: we started off as a prototype Meteor app. For ease of development, Meteor encourages developers to use Mongo for backend storage. Meteor internally uses the Mongo oplog to monitor updates from across the app. Some of these updates are pushed down to the client over persistent WebSocket connections. This all works great when you only have a few users, but it has significant overhead when scaling to thousands of users and many more database writes.
With some quick analysis we correlated our slow performance with new users signing up. This meant the bottleneck was our contact-syncing feature. When a new user signs up for Mixmax, we sync their Google Contacts into our secure database so they have all their contacts available when composing a new Mixmax message. The architecture was simple: we simply queried contacts using the Google API and wrote them directly into our Mongo database. We then set up a new Meteor subscription that watched the database and returned results real time.
This naive architecture was inefficient in many ways. First, contact syncing happened on the same server as the app. Syncing took 92 seconds (90th percentile) and consumed 100% for most of the time while it downloaded, parsed, and inserted the contacts into Mongo. The result was the CPU being pinned at 100%:
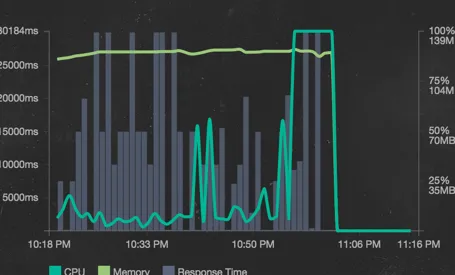
This caused users to lose their connection to the app if they had the misfortunte of being connected to a server that was syncing a new user. It was clear that we needed to rethink our architecture in a big way to begin scaling it to thousands. Our solution was to move to a microservices architecture, starting with the contacts system. Microservices make it much easier to scale each component of our app while keeping the other parts stable.
Moving contact syncing off into a separate microservice
We set up a new microservice that was the “syncing box”, solely responsible for syncing users’ contacts when they signed up for Mixmax. We set up Kue as a job queue for the sync jobs so only one ran at a time on each box. With our PaaS Modulus, we could easily change the number of workers by changing a slider in their UI. We used Compose.io for hosted Redis that Kue would sit on top of.
Additionally, Kue has a nice built-in UI for managing jobs:
The result was an immediate improvement. No longer did the Meteor boxes get consumed when a new user signed up. Things were starting to look much better.
This solution worked well for us for a few days. However, when a lot users signed up within the same minute (we had about one signup every 9 seconds), we noticed the app server’s CPU was still getting consumed. But why was this happening if the database writing was offloaded to the new server? Well, our naive client-side implementation set up a new Meteor subscription when the user started typing in the ‘to’ field in Mixmax. This required that Meteor tail the oplog for the database collection. The net result was that even after syncing and writing just 10,000 contacts to database, the app CPU was consumed for many seconds afterwards:
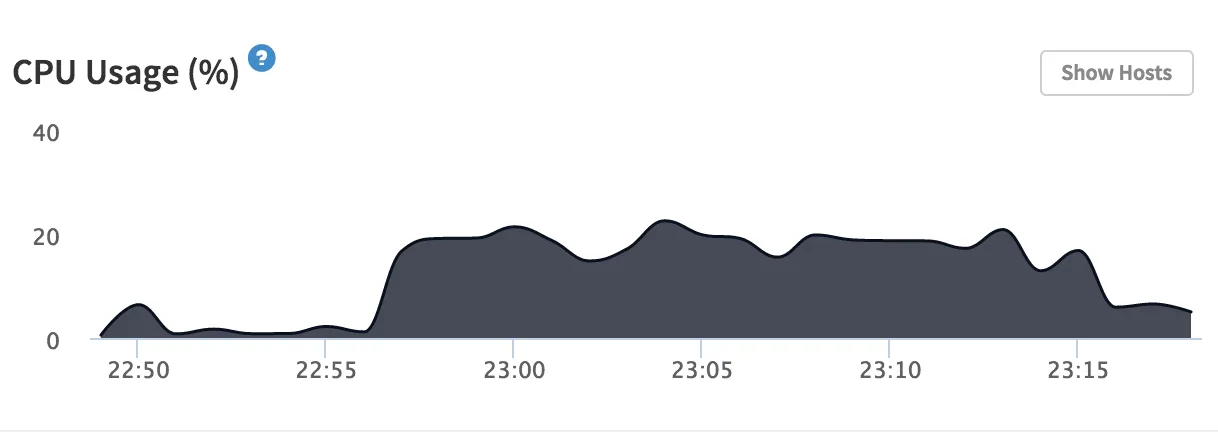
Moving contacts into their own database
The CPU spike was due to Meteor’s LiveQuery which was trying to keep up with thousands of contacts being inserted into Mongo. If there’s a subscription registered with the collection, as we have in this case, Meteor will watch the collection and process every update. When we’re writing 10,000 contacts per user within a minute, this causes a CPU spike of about 30 seconds, starving CPU resources from the application itself. Users were complaining about slow load times and not being able to log in (because other Meteor subscriptions were getting dropped).
However, when syncing a large amount of contacts, we still noticed the CPU still spiked a bit. It turns out that removing the Meteor subscription from the recent contacts database wasn’t enough: even storing contacts in the same database that Meteor is watching causes the oplog to overwhelm Meteor. This was a known issue with Meteor and it has since been fixed.

So the solution was to move the contacts off into their own database, completely cut off from Meteor. The result was instant: the servers running Meteor immediately returned to a normal CPU % and all was well.
Contact syncing and querying was just the first of several Mixmax subsystems that we moved out to microservices. Look for future blog posts about moving other key parts of Mixmax infrastructure out of the monolithic Meteor codebase into microservices. This is one of many ways we’re making the Mixmax infrastructure scalable, secure, and fast. Want to work on interesting problems like these? Email careers@mixmax.com and let’s grab coffee!