











This blog post is part of the Mixmax 2016 Advent Calendar. The previous post on December 5th was about securing server-side requests with JWT tokens.
tl;dr - we achieved a 30x performance improvement in Elasticsearch queries by switching from millisecond timestamps to seconds.
The problem
The live feed in Mixmax queries across half a billion documents in order to produce a chronological feed of your activity.
We use Elasticsearch to power this, but noticed some of our queries performed quite poorly (300-500ms), particularly during periods of peak load.
Digging into the problem, we noticed it was isolated to queries which involved a timestamp.
We mostly use Javascript here at Mixmax, so date/times across all our systems tend to be stored as epoch timestamps in milliseconds. Elasticsearch is no exception. Here’s a sample of how our indexes are defined:
{
userId: { type: 'string', index: 'not_analyzed' },
timestamp: {
type: 'date',
format: 'epoch_millis'
},
...
}Note we’re using Elasticsearch’s built-in date type with format: epoch_millis. You can read more about the different supported date formats in their docs.
The solution
Recreating a sample cluster locally, we noticed that performance improved dramatically if we stored and queried upon our timestamps in seconds e.g.:
{
userId: { type: 'string', index: 'not_analyzed' },
timestamp: {
type: 'date',
format: 'epoch_millis'
},
timestamp_seconds: {
type: 'date',
format: 'epoch_second'
}
}We then setup some profiling code and ran the following two queries across a test set of 500 million documents:
// Run a simple query, sorting by the millisecond timestamp.
console.log(client.search({
index: ...,
body: {
query: {
bool: {
filter: {
{ term: { userId: ... } }
}
}
}
},
sort: 'timestamp:desc'
}));
// Output: { took: 268 }
// Run the same query, sorting by the second timestamp.
console.log(client.search({
index: ...,
body: {
query: {
bool: {
filter: {
{ term: { userId: ... } }
}
}
}
},
sort: 'timestamp_seconds:desc'
}));
// Output: { took: 7 }That’s over 30x faster.
We also tested the improvement under various loads:
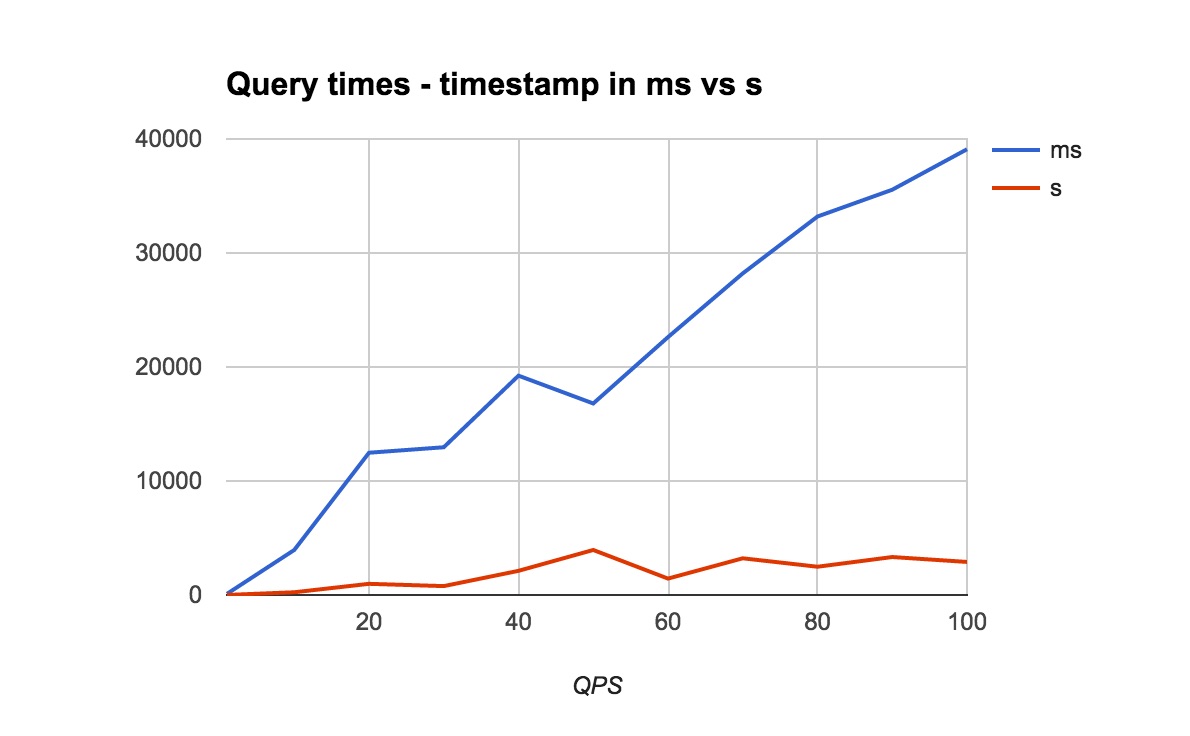
We were curious if we could improve performance even further by using timestamps rounded to the nearest minute and hour, but sadly we only saw negligible performance gains.
All of this was very exciting, but also kinda weird. Why would it make a difference whether we use milliseconds or seconds? We’re Elasticsearch newbs, so we checked in with the experts over at the elastic.co forums.
I’ll repeat Adrian Grand’s (Software Engineer at Elastic) answer here:
To have acceptable performance for range queries, numeric fields also index some prefix terms. For instance long values (which dates are based on) index 4 values by default: one that identifies all bits, one that identifies the first 48 bits, one that identifies the first 32 bits and one that identifies the first 16 bits. These prefix terms help querying fewer terms at search time, which makes search faster: queries typically try to use these terms that match multiple terms and just need to match exact values on the edge of the range. But since we use a precision step of 16 bits, there can still be op to 2^16=65536 values on the edges. However, if your dates are all multiples of 1000, suddenly, there are only ~66 unique values at most on the edges, which helps querying be faster.
He also mentioned that in the next major release (we’re currently on 2.3.3), querying will be tree-based, so the performance profile for these kinds of queries will change.
So there you go: moral of the story - don’t use millisecond timestamps in Elasticsearch if seconds will do!
Enjoy solving engineering puzzles like this one? Drop us a line.

